Today I learned
- 데이터베이스 (DB 특강)
데이터베이스(Database, DB)란?
데이터베이스는 데이터의 집합이라고 할 수 있다
DBMS란 무엇인가?
데이터베이스를 관리하는 소프트웨어를 DBMS라고 한다
파일로 데이터를 관리한다면 많은 사람이 데이터에 접근하려고 할 때 각자 다른 파일을 가지고 있어야한다
그렇다면 데이터의 영속성과 무결성이 깨진다 여러사람이 데이터 접근하고 공유하려면 필요한게 DMBS다

DBMS의 종류

DBMS의 분류는 계층형, 망형, 관계형으로 구분이 되어있다 관계형DMBS를 줄여서 RDBMS라고 부른다
MySQL뿐 아니라 대부분의 DBMS가 RDBMS 형태로 사용한다
RDBMS는 테이블이라는 최소 단위로 구성되고 테이블(Table)은 하나 이상의 행(Row), 열(Col)로 이루어진다
SQL은 DBMS에서 사용하는 언어이다 관계형 DBMS중 MySQL을 배우려면 SQL은 필수로 알아야한다
일반적이 프로그래밍 언어와는 조금 다른 특성을 가진다
SQL과 NO SQL

SQL은 정해진 틀에 따라 테이블에 저장한다 그래서 장점으로는 명확하게 정의된 스키마, 데이터 무결성이 보장된다
관계는 각 데이터를 중복없이 한 번만 저장한다 단점으로는 정해진 틀에 따라야하기 때문에 유연하지 못하다 나중에 수정하기 힘들기 때문에 사전 계획을 잘 준비해야한다 관계를 맺고 있어서 조인문이 많이 복잡한 쿼리가 만들어 진다
대체로 수직적인 확장만 가능하다 제품은 MySQL, PostgreSQL, Oracle등이 있다
NO SQL은 데이터를 자유롭고 다양한 형태로 저장한다 정해진 구조가 없고 관계도 없다 그래서 장점으로는 틀이 없기 때문에 유연하고 언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있다 데이터는 애플리케이션이 필요로 하는 형식으로 저장된다 데이터를 읽어는 속도가 빠르다 수직 및 수평으로 확장이 가능해서 애플리케이션이 발생시키는 모든 읽기/쓰기 요청 처리가 가능하다 단점으로는 유연하기 때문에 데이터 구조 결정을 미루게 될 수 있다 데이터의 중복을 계속 업데이트 해야한다 데이터가 여러 컬렌션에 중복이 되어 있기 때문에 수정 시 모든 컬렌션에서 수행을 해야한다
제품으로는 MongoDB, Firestore, Redis등이 있다.
DB Naming Convention
스키마의 이름을 작성할 때 잘 작성해야한다!
소문자를 사용한다 실수할 일이 적고 MySQL은 대소문자를 구분하기에 통일해준다
space는 사용하지말고 Underscore _로 사용한다
숫자는 허용하지 않는다
Col의 의미를 설명가능한 이름이고 64자를 넘지 않는다
prefix를 사용하지 않는다
데이터베이스 이름
단수형, 복수형 모두 사용할 수 있지만 데이터베이스 자체가 1개의 데이터들의 모음을 나타내니까 단수형으로 만들자
가능한 prefix는 피하자
테이블 이름
소문자를 사용한다 대소문자를 구분하는 리눅스 서버 위에 보통 MySQL을 호스팅한다 또 MySQL과 함꼐 사용되는 많은
프레임워크들이 자동 생성해주는 테이블이름이 소문자를 사용한다
테이블 이름은 단수형으로 한다 테이블은 하나의 독립체!
prefix를 사용한다 테이블은 일반적으로 데이터베이스 혹은 프로젝트의 이름을 가지고 있다
한 데이터베이스 내에서드 비슷한 역할을 하는 테이블이름이 겹칠 수 있으므로 테이블 이름에 prefix를 사용한다
필드 이름(Colume name)
소문자 사용, 스페이스 금지, 숫자 사용 금지, prefix 금지
짧아야 한다 2개 단어를 넘지 말자
이해하기 쉬워야한다
기본키는 id혹은 <table_name>_id의 형태
단어를 거꾸로 쓰는 일은 피하자 (date_signup(x), date_create(x), signup_date(o), created_date(o))
컬럼명과 테이블이름을 동일하게 하지말자
축약형, 연결형, 두음형을 피하자
외래키를 사용한다
외래키 컬럼명에는 참조하는 테이블 이름을 사용하자
DB, Table 생성, 수정, 삽입, 삭제 연습!
DB 생성
CREATE DATABASE sparta_test;
DB 선택
USE sparta_test;
DB 삭제
DROP DATABASE sparta_test;
Table 생성
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT
,
name VARCHAR(50) NOT NULL
,
email VARCHAR(50) UNIQUE
);
Table 삭제
DROP TABLE student;
데이터 삽입
INSERT
INTO
student (name, email)
VALUES
("테스트1", "test1@gmail.com")
,
("테스트2", "test2@gmail.com")
,
("테스트3", "test3@gmail.com");
데이터 삭제
DELETE
FROM
student
WHERE
id = 1;
데이터 수정
UPDATE
student
SET
email = "test@gmail.com"
WHERE
id = 3;학생 테이블 (city_id) 추가 및 외래키 및 조인
ALTER TABLE student ADD city_id INT NULL
,
ADD CONSTRAINT student_FK FOREIGN KEY (city_id) REFERENCES sparta_test.city(id) ON
DELETE
CASCADE ON
UPDATE
CASCADE;
SELECT * FROM student s INNER JOIN city c ON s.city_id = c.id;
학생 데이터 검색 LIKE 와일드카드
SELECT
*
FROM
student s
WHERE
email LIKE "%@gmail%";
데이터베이스 설계
데이터베이스 설계 순서

개념적 모델링은 개체와 개체들 간의 관계에서 ER다이어그램을 만드는 과정이다
ER모델은 세상의 모든 사물을 개체(Entity)와 개체 간의 관계(Relationship)으로 표현

관계타입의 유형
1 : 1 관계(일 대 일)
개체 집합 A의 각 원소가 개체 집합 B의 원소 1개와 대응
1 : N 관계(일 대 다)
개체 집합 A의 각 원소는 개체 집합 B의 원소 여러 개와 대응할 수 있고, 개체 집합 B의 각 원소는 개체 집합 A의 원소 1개와 대응
N : M 관계(다 대 다)
개체 집합 A의 각 원소는 개체 집합 B의 원소 여러개와 대응할 수 있고, 개체 집합 B의 각 원소는 개체 집합 A의 원소 여러 개와 대응할 수 있음
논리적 모델링은 ER다이어그램을 사용하여 관계 스키마 모델을 만드는 과정이다
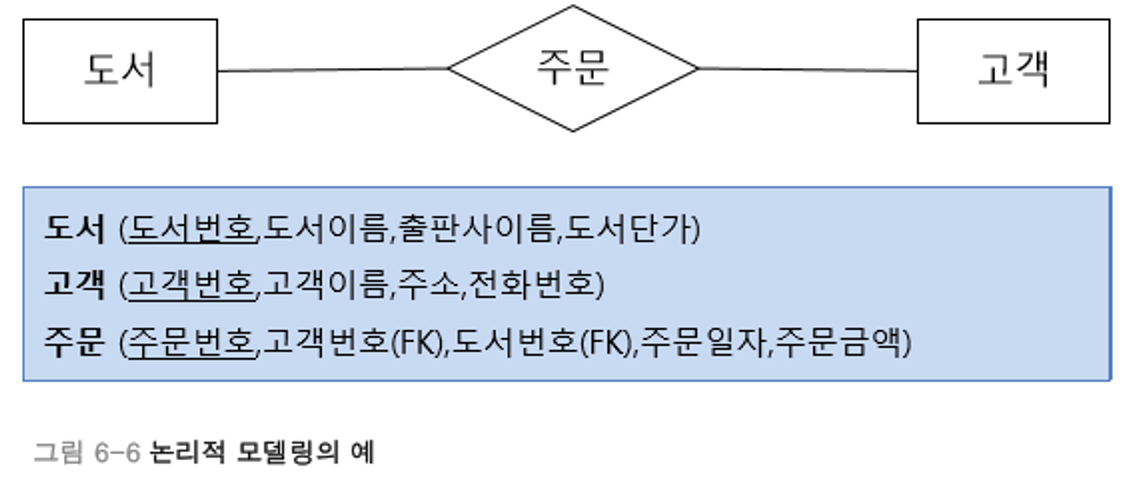
물리적 모델링은 관계 스키마 모델의 물리적 구조를 정의하고 구현하는 과정이다

그리고 마지막으로 데이터베이스를 구현한다!
데이터베이스 정규화(Normalization)
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화 하는 프로세서를 정규화라고 한다
정규화의 기본 목표는 관련없는 함수 종속성은 별개의 릴레이션으로 표현한다
정규화된 결과를 정규형이라고 하며, 정규형은 기본 정규형과 고급 정규형으로 나눈다
기본정규형의 제1, 제2, 제3 정규형만 먼저 알아보자
제 1정규형 더 이상 분해되지 않는 원자값으로만 구성된 정규형이다

제2 정규형은 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속 되면 제 2 정규형이다
제1 정규형을 제2 정규형을 만족하려면 부분 함수 종속을 제거하고 환전 함수 종속이 되도록 분해하는 정규화를 해야한다완전 함수 종속은 어떤 속성이 기본키에 대해 완전히 종속일 때
부분 함수 종속은 어떤 속성이 기본키가 아닌 다른 속성에 종속되거나, 기본키가 여러 속성으로 구성되어 있을경우 기본키를 구성하는 속성 중 일부만 종속될 때
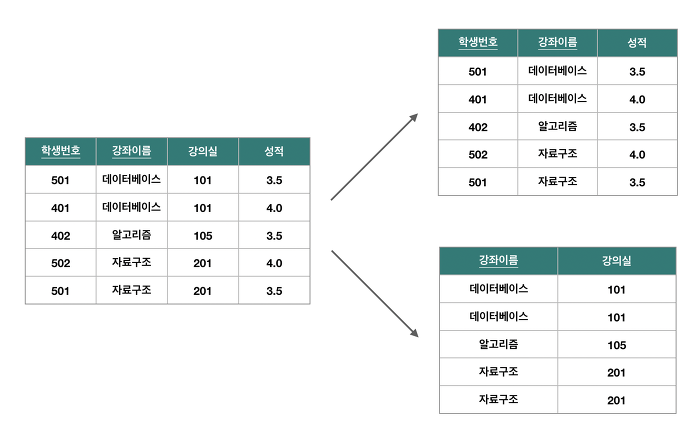
제3 정규형 이행적 함수 종속이 되지 않는 것
이행적 함수 종속은 A ---> B, B ---> C인 경우 A ---> C가 성립될 때
즉 A를 알면 B를 알고 C를 알 수 있는 경우를 의미
'과거공부모음' 카테고리의 다른 글
| 나의 개발일지 TIL(Today I learned) - OSI 7계층 특강, 미니프로젝트 시작 (1일) (0) | 2022.12.02 |
|---|---|
| 나의 개발일지 TIL(Today I learned) - rest API, HTML, CSS, Javascript 특강 (0) | 2022.12.01 |
| 나의 개발일지 TIL(Today I learned) - 자료구조와 알고리즘(트리, 힙, 그래프, BFS, DFS, 타임어택 문제풀기) (0) | 2022.11.29 |
| 나의 개발일지 TIL(Today I learned) - 자료구조와 알고리즘(해시) (1) | 2022.11.28 |
| 나의 개발일지 WIL(Weekly I learned) - 자료구조와 알고리즘 (0) | 2022.11.27 |


